介绍
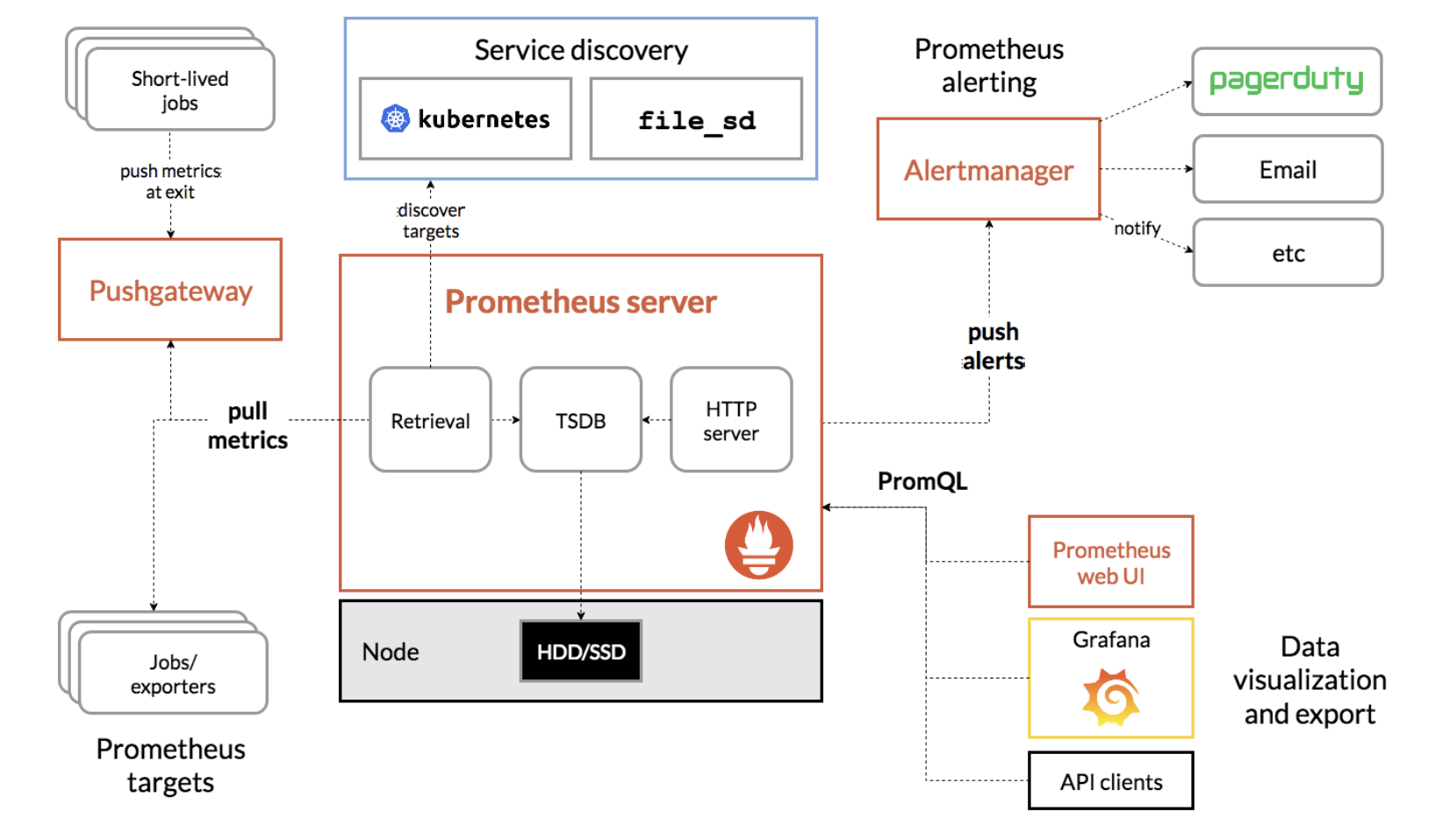
此图说明了Prometheus的架构及其生态系统组件:
部署
通过K8S部署,包含node、server、alertmanager和grafana。通过kubectl apply -f [文件名]运行即可。
根据所列出的配置文件部署进行部署,则
- 30001端口为altermanager
- 30003端口为Prometheus Server UI
- 30005端口为Grafana UI
node
使用daemonSet实现每个Node节点均部署node-exporter。server通过自动发现拉取各Node节点暴露出的指标。
node-exporter.yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: node-exporter
namespace: monitor
labels:
k8s-app: node-exporter
spec:
selector:
matchLabels:
k8s-app: node-exporter
template:
metadata:
labels:
k8s-app: node-exporter
spec:
containers:
- image: prom/node-exporter
name: node-exporter
ports:
- containerPort: 9100
protocol: TCP
name: http
---
apiVersion: v1
kind: Service
metadata:
labels:
k8s-app: node-exporter
name: node-exporter
namespace: monitor
spec:
ports:
- name: http
port: 9100
nodePort: 31672
protocol: TCP
type: NodePort
selector:
k8s-app: node-exporter
server
server除了deploy及svc外,还包含RBAC认证、configMap配置文件,目录文件如下:

rbac-README.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: prometheus
namespace: monitor
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: prometheus
rules:
- apiGroups:
- ""
resources:
- nodes
- nodes/proxy
- services
- endpoints
- pods
verbs:
- get
- list
- watch
- apiGroups:
- extensions
resources:
- ingresses
verbs:
- get
- list
- watch
- nonResourceURLs:
- "/metrics"
verbs:
- get
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: prometheus
namespace: monitor
roleRef:
kind: ClusterRole
name: prometheus
apiGroup: rbac.authorization.k8s.io
subjects:
- kind: ServiceAccount
name: prometheus
namespace: monitor
apiGroup: rbac.authorization.k8s.io
rbac-setup.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: prometheus
rules:
- apiGroups: [""]
resources:
- nodes
- nodes/proxy
- services
- endpoints
- pods
verbs: ["get", "list", "watch"]
- apiGroups:
- extensions
resources:
- ingresses
verbs: ["get", "list", "watch"]
- nonResourceURLs: ["/metrics"]
verbs: ["get"]
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: prometheus
namespace: monitor
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: prometheus
namespace: monitor
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: prometheus
subjects:
- kind: ServiceAccount
name: prometheus
namespace: monitor
configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
namespace: monitor
data:
prometheus.yml: |
global:
scrape_interval: 15s
evaluation_interval: 15s
alerting:
alert_relabel_configs:
- source_labels: [dc]
regex: (.+)\d+
target_label: dc1
alertmanagers:
- static_configs:
- targets: ["192.168.254.23:30001"] # 这是alertmanager应用对外暴露的端口
rule_files:
- /etc/rules/*.yaml
scrape_configs:
- job_name: 'kubernetes-apiservers'
kubernetes_sd_configs:
- role: endpoints
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: default;kubernetes;https
- job_name: 'kubernetes-nodes'
kubernetes_sd_configs:
- role: node
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- target_label: __address__
replacement: kubernetes.default.svc:443
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics
- job_name: 'kubernetes-cadvisor'
kubernetes_sd_configs:
- role: node
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- target_label: __address__
replacement: kubernetes.default.svc:443
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor
- job_name: 'kubernetes-service-endpoints'
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
action: replace
target_label: __scheme__
regex: (https?)
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]
action: replace
target_label: __address__
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: kubernetes_name
- job_name: 'kubernetes-services'
kubernetes_sd_configs:
- role: service
metrics_path: /probe
params:
module: [http_2xx]
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_probe]
action: keep
regex: true
- source_labels: [__address__]
target_label: __param_target
- target_label: __address__
replacement: blackbox-exporter.example.com:9115
- source_labels: [__param_target]
target_label: instance
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
target_label: kubernetes_name
- job_name: 'kubernetes-ingresses'
kubernetes_sd_configs:
- role: ingress
relabel_configs:
- source_labels: [__meta_kubernetes_ingress_annotation_prometheus_io_probe]
action: keep
regex: true
- source_labels: [__meta_kubernetes_ingress_scheme,__address__,__meta_kubernetes_ingress_path]
regex: (.+);(.+);(.+)
replacement: ${1}://${2}${3}
target_label: __param_target
- target_label: __address__
replacement: blackbox-exporter.example.com:9115
- source_labels: [__param_target]
target_label: instance
- action: labelmap
regex: __meta_kubernetes_ingress_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_ingress_name]
target_label: kubernetes_name
- job_name: 'kubernetes-pods'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: kubernetes_pod_name
- job_name: 'prod-node-exporter' # 用于监控主机状态
static_configs:
- targets: ['[IPADDRESS]:[PORT]','[IPADDRESS]:9100'] # 需要先将node-exporter进行部署,并暴露端口
labels:
group: 'prod-node' # 额外打上标签,方便汇总查看
- job_name: 'prod-cAdvisor' # 用于监控容器状态
static_configs:
- targets: ['[IPADDRESS]:[PORT]','[IPADDRESS]:9101']
labels:
group: 'prod-cAd'
通过Prometheus UI显示的实例标签如下,之后使用Grafana的时候也会通过该标签进行可视化输出。

alerting_rules.yaml
该文件只用于配置告警规则,冗余规则通过alertmanager-conf.yaml配置。
apiVersion: v1
kind: ConfigMap
metadata:
name: alerting-rules
namespace: monitor
data:
alerting_rules.yaml: |
groups:
- name: node
rules:
- alert: InstanceDown
expr: up == 0
for: 3m
labels:
severity: error
send: manager
annotations:
summary: "Instance {{ $labels.instance }} down"
- alert: Disk Alarm # 告警名称
expr: 100 - ((node_filesystem_avail_bytes{mountpoint="/",fstype!="rootfs"} * 100) / node_filesystem_size_bytes{mountpoint="/",fstype!="rootfs"}) > 80 # PromQL表达式
for: 3m
labels:
severity: notice # 告警级别
send: manager # 发送给指定组,该组包含的用户通过alertmanager-conf.yaml配置
annotations:
summary: "Warning: Disk usage reaches 80%" # 发送的消息包含的注释
- alert: Memory Alarm
expr: (node_memory_Active_anon_bytes/node_memory_MemTotal_bytes)*100 > 80
for: 3m
labels:
severity: warn
send: manager
annotations:
summary: "Memory usage reaches 80%"
- alert: CPU Alarm
expr: 100 * (1 - sum by (instance)(increase(node_cpu_seconds_total{mode="idle"}[5m])) / sum by (instance)(increase(node_cpu_seconds_total[5m]))) > 37.5
for: 3m
labels:
severity: warn
send: default
annotations:
summary: "CPU usage reaches 30%"

prometheus.svc.yaml
kind: Service
apiVersion: v1
metadata:
labels:
app: prometheus
name: prometheus
namespace: monitor
annotations:
prometheus.io/scrape: 'true'
prometheus.io/port: '9090'
spec:
type: NodePort
ports:
- port: 9090
targetPort: 9090
nodePort: 30003
selector:
app: prometheus
prometheus.deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
name: prometheus-deployment
name: prometheus
namespace: monitor
spec:
replicas: 1
selector:
matchLabels:
app: prometheus
template:
metadata:
labels:
app: prometheus
spec:
containers:
- image: 192.168.254.29:8080/library/prom/prometheus:19.03.8
name: prometheus
command:
- "/bin/prometheus"
args:
- "--config.file=/etc/prometheus/prometheus.yml"
- "--storage.tsdb.path=/prometheus"
- "--storage.tsdb.retention=24h"
- "--web.enable-admin-api"
- "--web.enable-lifecycle"
ports:
- containerPort: 9090
protocol: TCP
volumeMounts:
- mountPath: "/prometheus"
name: data
- mountPath: "/etc/prometheus"
name: config-volume
- mountPath: "/etc/rules"
name: prometheus-alerting-rules-volume
- mountPath: "/etc/localtime"
name: date
resources:
requests:
cpu: 100m
memory: 100Mi
limits:
cpu: 500m
memory: 2500Mi
serviceAccountName: prometheus
volumes:
- name: data
emptyDir: {}
- name: config-volume
configMap:
name: prometheus-config
- name: prometheus-alerting-rules-volume
configMap:
name: alerting-rules
- name: date
hostPath:
path: /etc/localtime
alertmanager
Prometheus的告警功能单独拉出来由Altermanager实现,这也是符合云原生和微服务的规划,即告警功能的缺失并不影响监控功能的运行。所以altermanager需要单独使用deploy部署实现。
alertmanager-deploy.yaml
顺便提一嘴,根据K8S的最佳实践,Service推荐在Deploy之前实现,应该是在Pod调度的时候效率更高,不然部署完后再根据Service进行调度可能会造成一定开销。
---
kind: Service
apiVersion: v1
metadata:
labels:
app: alertmanager
name: alertmanager
namespace: monitor
spec:
type: NodePort
ports:
- port: 9093
targetPort: 9093
nodePort: 30001
selector:
app: alertmanager
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
name: alertmanager-deployment
name: alertmanager
namespace: monitor
spec:
replicas: 1
selector:
matchLabels:
app: alertmanager
template:
metadata:
labels:
app: alertmanager
spec:
containers:
- image: harbor.wlhiot.com:8080/library/prom/alertmanager:19.03.8
name: alertmanager
args:
- "--config.file=/etc/alertmanager/config.yml"
- "--storage.path=/alertmanager/data"
ports:
- containerPort: 9093
name: http
volumeMounts:
- mountPath: "/etc/alertmanager"
name: alertcfg
resources:
requests:
cpu: 100m
memory: 256Mi
limits:
cpu: 100m
memory: 256Mi
volumes:
- name: alertcfg
configMap:
name: alert-config
alertmanager-conf.yaml
通过配置文件实现不同的告警级别发送不同的邮件给不同的接收人,来实现告警的冗余。
apiVersion: v1
kind: ConfigMap
metadata:
name: alert-config
namespace: monitor
data:
config.yml: |-
global:
# 在没有报警的情况下声明为已解决的时间
resolve_timeout: 5m
# 配置邮件发送信息
smtp_from: xxx # 账号
smtp_smarthost: xxx # 发件服务器
# smtp_hello: default is localhost
smtp_auth_username: xxx # 认证账号
smtp_auth_password: xxx # 认证密码
smtp_require_tls: false
# 所有报警信息进入后的根路由,用来设置报警的分发策略
route:
# 默认的receiver:如果一个报警没有被一个route匹配,则发送给默认的接收器
receiver: default
# 这里的标签列表是接收到报警信息后的重新分组标签,例如,接收到的报警信息里面有许多具有 cluster=A 和 alertname=LatncyHigh 这样的标签的报警信息将会批量被聚合到一个分组里面
group_by: ['alertname', 'cluster']
# Whether an alert should continue matching subsequent sibling nodes.
# continue: True
# 当一个新的报警分组被创建后,需要等待至少group_wait时间来初始化通知,这种方式可以确保您能有足够的时间为同一分组来获取多个警报,然后一起触发这个报警信息。
group_wait: 2m
# 当第一个报警发送后,等待'group_interval'时间来发送新的一组报警信息。
group_interval: 1m
# 如果一个报警信息已经发送成功了,等待'repeat_interval'时间来重新发送他们
repeat_interval: 1d
# 上面所有的属性都由所有子路由继承,并且可以在每个子路由上进行覆盖。
routes:
- match:
send: manager
receiver: manager
receivers:
- name: default
email_configs:
- send_resolved: true
to: xxx@xxx.com # 接收人
- name: manager
email_configs:
- send_resolved: true
to: xxx@xxx.com # 接收人
grafana
grafana用于将server采集到数据进行可视化,可以通过https://grafana.com/grafana/dashboards/?search=node+export来配置自己需要的模板,推荐两个模板
- 11074 用于监控主机
- 315 用于监控K8S Node节点

pv.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfspv01
spec:
capacity:
storage: 10Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Recycle
storageClassName: grafana
nfs:
path: /usr/local/wlhiot/mount/nfsdata/nfspv01
server: 192.168.254.29 # 我这边是使用nfs的组件来实现storageclass存储
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: grafana-pvc
namespace: monitor
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
storageClassName: grafana
grafana.yaml
---
apiVersion: v1
kind: Service
metadata:
name: grafana-officail
namespace: monitor
labels:
app: grafana-officail
spec:
type: NodePort
ports:
- port: 3000
targetPort: 3000
nodePort: 30005
selector:
app: grafana-officail
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: grafana-official
name: grafana-officail
namespace: monitor
spec:
selector:
matchLabels:
app: grafana-officail
template:
metadata:
labels:
app: grafana-officail
spec:
securityContext:
fsGroup: 472
supplementalGroups:
- 0
containers:
- name: grafana-officail
image: grafana/grafana:7.5.2
imagePullPolicy: IfNotPresent
ports:
- containerPort: 3000
name: http-grafana
protocol: TCP
readinessProbe:
failureThreshold: 3
httpGet:
path: /robots.txt
port: 3000
scheme: HTTP
initialDelaySeconds: 10
periodSeconds: 30
successThreshold: 1
timeoutSeconds: 2
livenessProbe:
failureThreshold: 3
initialDelaySeconds: 30
periodSeconds: 10
successThreshold: 1
tcpSocket:
port: 3000
timeoutSeconds: 1
resources:
requests:
cpu: 250m
memory: 750Mi
volumeMounts:
- mountPath: /var/lib/grafana
name: grafana-pv
volumes:
- name: grafana-pv
persistentVolumeClaim:
claimName: grafana-pvc